Save yourself from Krampus with ML.NET and F#
Published 2020-12-25
This is the first year I've ever contributed to the F# Advent Calendar. For this very special occasion I thought it would make sense to give you a glimpse into the christmas traditions of my country - Austria. If you have never been to the Alpine regions of Europe you might have never heard of Krampus. Krampus is St. Nicholas' sidekick who punishes naughty children. Most christmas mythologies have some figure, that has the role of St. Nick's evil counterpart. This special character just happens to be a literal devil from the depths of hell, that beats you bloody in case you were a bad boy or girl. Having Krampus might seem a bit crass to outsiders but never forget: we're pretty catholic down here and by tradition "moral behavior" is taught to us from a very early age using a healthy mix of fear and violence. Good, that we live in modern times now and there is technology at our hands to keep us safe. Using F# and ML.NET we can build a complete end-to-end application, that uses machine learning to tell us if we can get something sweet from Santa or should hide away from evil Krampus.
What does end-to-end even mean in this context? Usually when I go through a tutorial to learn some machine learning concept I tend to find a prepared notebook, a tidy dataset and a predefined use case. I just have to fill in the last couple of steps and by the end I hopefully got some intuition about the concept I wanted to learn in isolation. That's fine but usually whenever I then try to build a more complete app myself I find out, that I'm at a loss. How do I get to the point where I can use my new knowledge? In this post I will try to take a look at the complete process. Wish me luck 🤞
The Big Picture
This post could become a tiny bit long so if you're in a rush here is the short version. I'm just one person building a end-to-end use case around a Christmas themed childhood trauma. Doing this "the conventional way" would usually need a couple of different programs, roughly three programming languages and a decent amount of shell scripting to glue some things together. In theory I could do all of those things but where would be the fun in that? Rather than doing that I'll just stick to using F# and a couple of community projects. Will it be the bleeding-edge of ML research? No. Is it a thing you could use in your apps today? Absolutely. An overview of what I'll show you:
- Data acquisition using Google image search semi automatically from an interactive notebook
- Data preparation with the help of simple SAFE utility application
- Training a Convolutional Neural Network (CNN) using transfer learning with ML.NET
- Building an application making use of the model
If you are interested in any particular part of the article just skip between whatever interests you. You can find all the source code and additional documentation in this repository. If you find something you like just take it and build something cool with it. If you have questions or feedback don't hesitate to open an issue.
Data Acquisition with Canopy
There are a ton of images on the internet. One of the easiest ways to get to the ones you want to have for your dataset is to just use a search engine like Google. Unfortunately, there isn't really an API (at least if you don't want to use Custom Search) to use image search programmatically. As many of Google's products, it isn't super accessible to machines (I hope the irony isn't lost on them). Good thing, that there is Canopy: a friendly F# API for selenium to simulate a human using a browser. This makes even JavaScript heavy applications which try to hide data from you (like Google search) pretty machine-accessible. If you want to see the complete code you can find it in the DataCollection.ipynb notebook in the accompanying repository.
let getImgUrls (n: int) (query: string) =
let searchUrl = getSearchUrl query
url searchUrl
sleep 1
let imagesToClick =
elements "div#islmp a.wXeWr.islib.nfEiy.mM5pbd img"
let toTake = min (List.length imagesToClick) n
let getImageUrl (elem : IWebElement) =
try
click elem
sleep 1
// nah this is not brittle and hacky as hell at all
elem |> parent |> parent |> fun e -> e.GetAttribute("href")
|> fun s -> s.Split('?').[1].Split('&').[0].Substring(7)
|> Uri.UnescapeDataString
|> Some
with
| e -> None
imagesToClick
|> List.take toTake
|> List.map getImageUrl
|> List.filter Option.isSome
|> List.map (Option.defaultValue String.Empty)
let queryString = "krampus"
let imgUrls = getImgUrls 50 queryString
Writing Canopy (or any Selenium code for that matter) is usually quite hacky. In this case I simulate user clicks on the image thumbnails because Google image search then adds the source URL to an element in the DOM. After a waiting for a bit (DOM updates aren't immediate) it is possible to grab the newly added href from two levels up the hierarchy. Finding out how to best access the things I want is usually an iterative process, probing around until I get lucky. I personally treat "foreign" web applications as hostile territory and therefore don't waste too much time on writing super stable and generalized code (as is proven by me using the mangled class names in the Google search app to query the page). It is brittle and it will be break in the future but for semi-automatic gathering of data samples it is usually good enough. In my experience it is one of the most efficient ways to get quick results - so I'm happy to live with this trade-off.
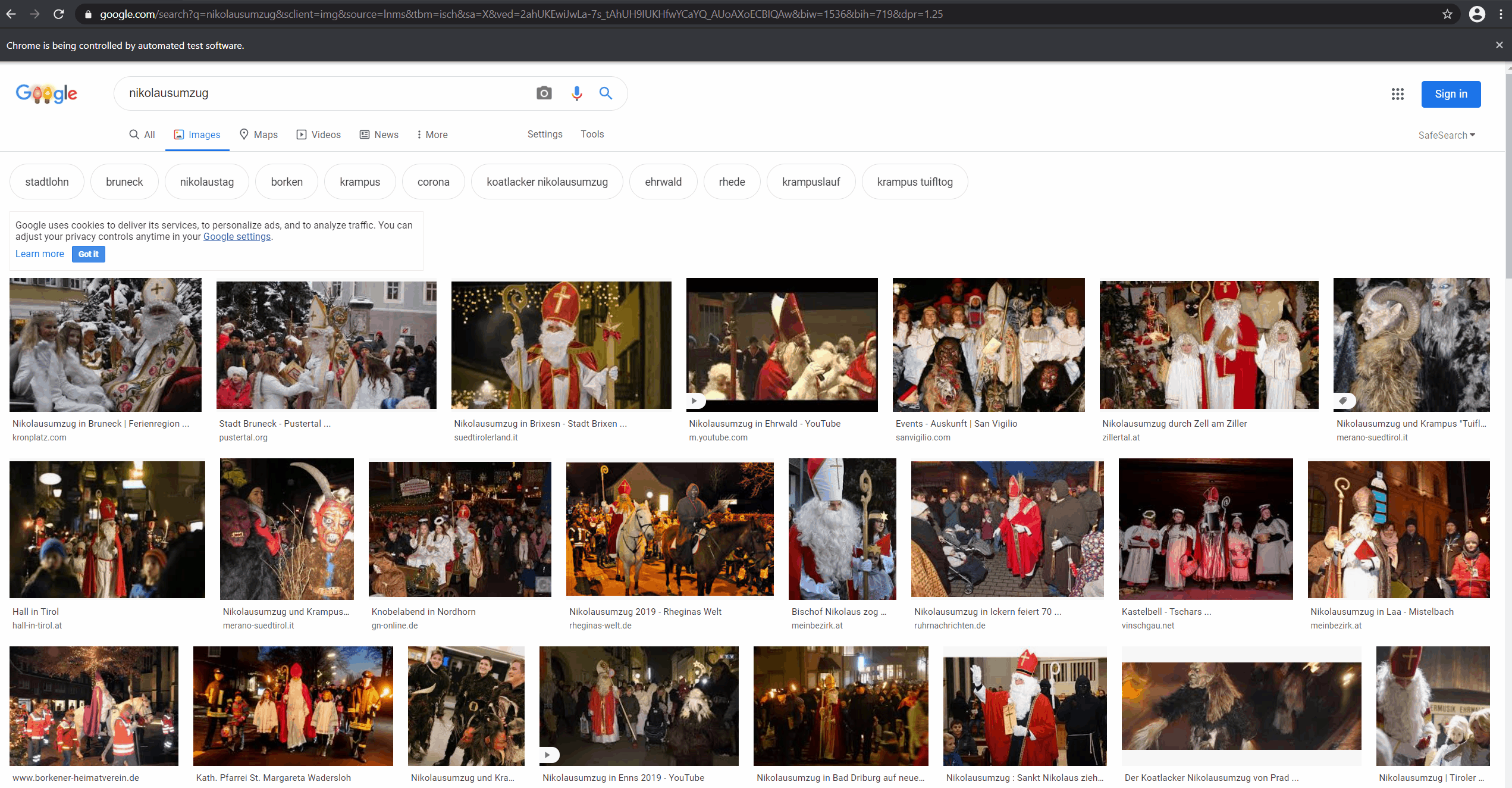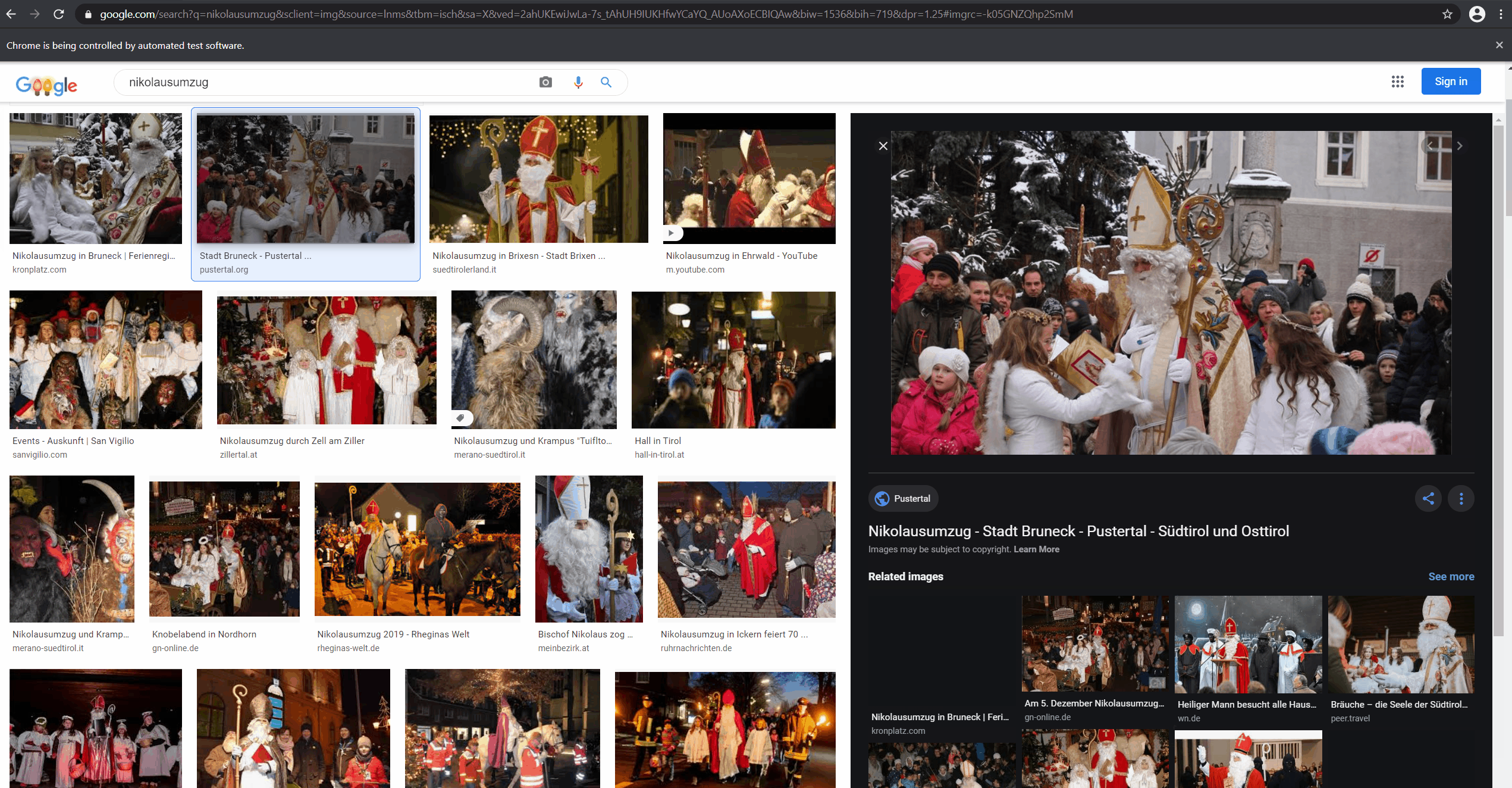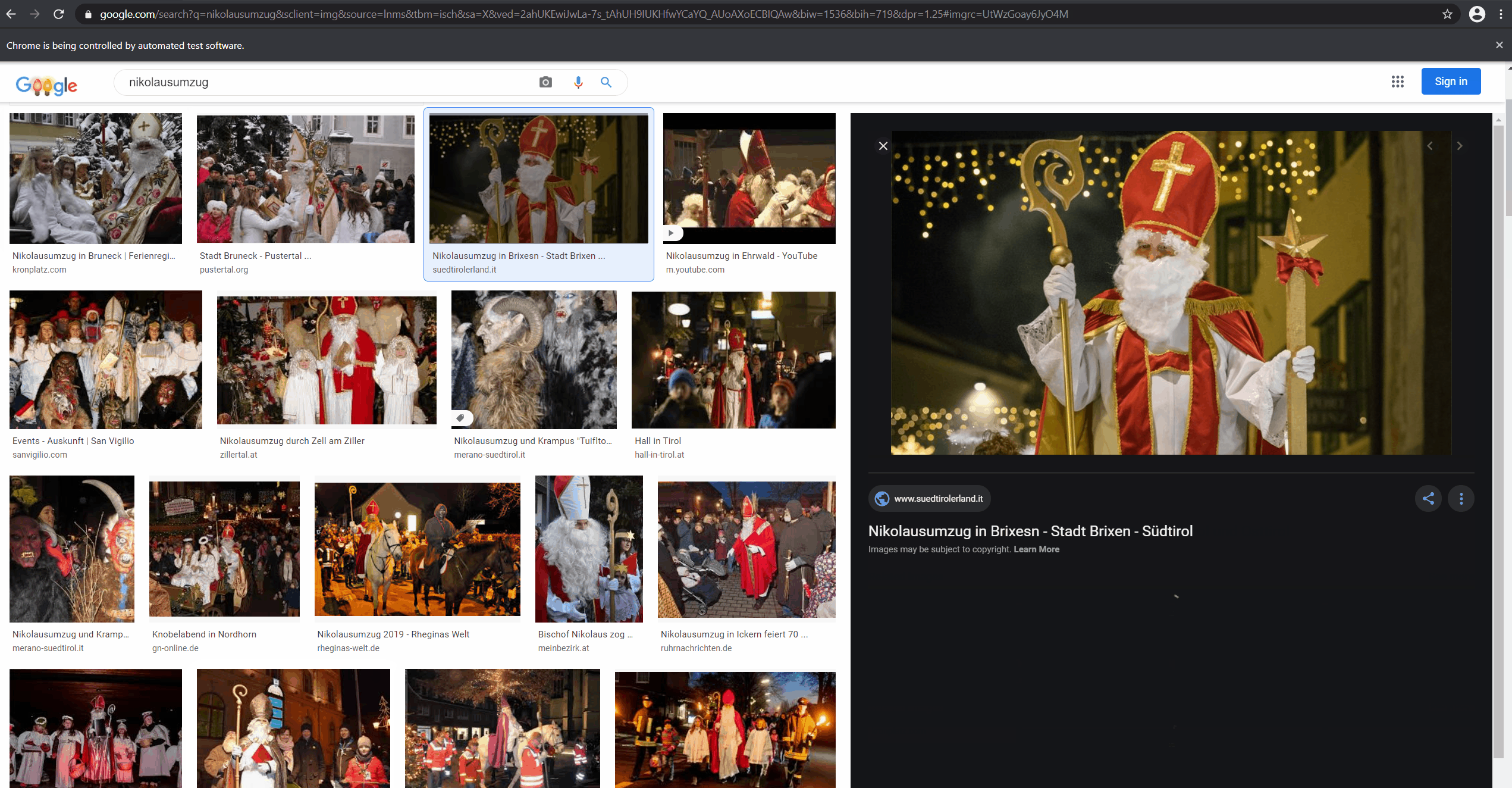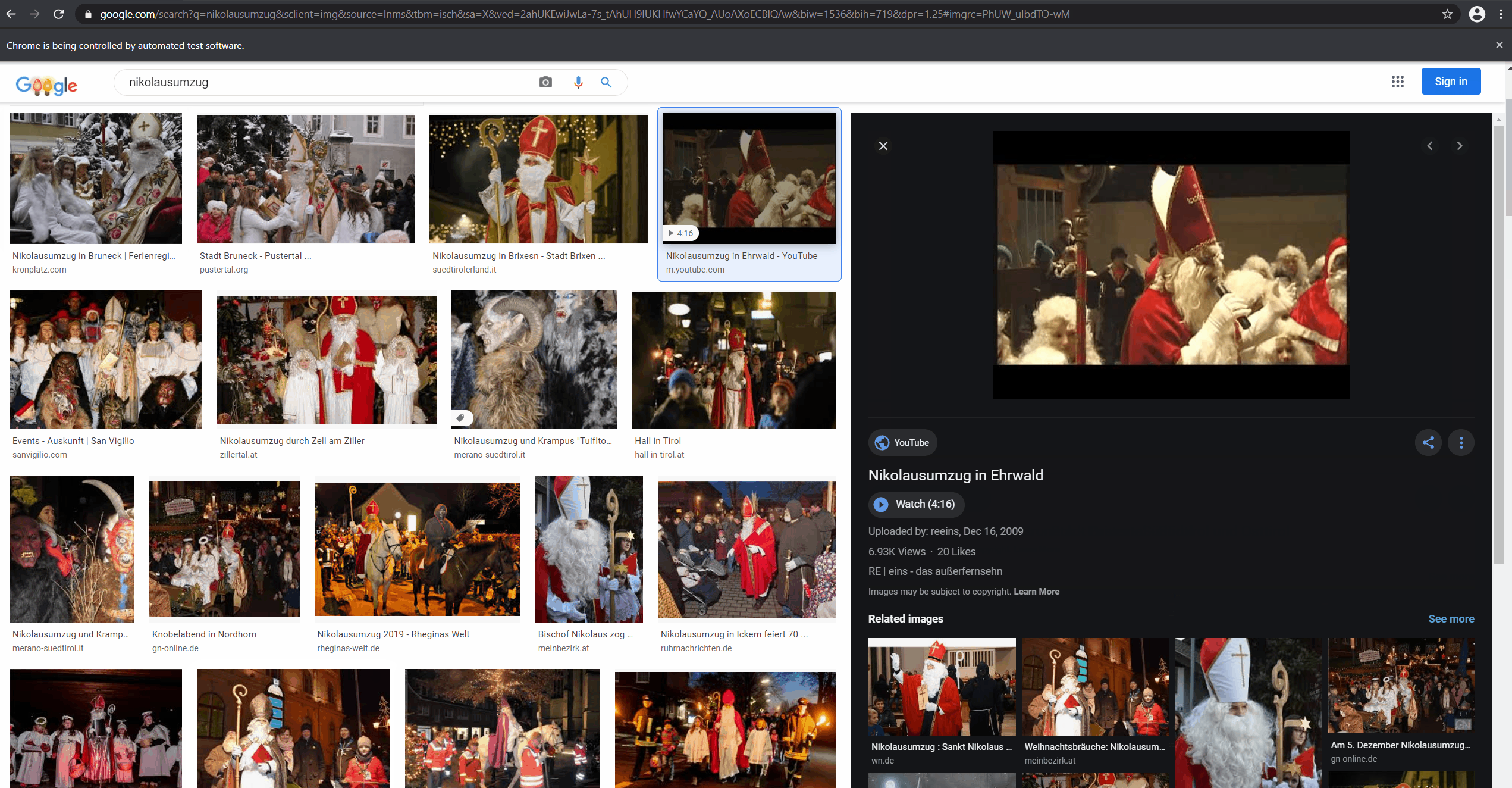
Look at it go! Downloading the images from the given URLs is a bit more straight forward.
let downloadImage (uri: string) =
let req =
try
httpClient.GetAsync uri
|> Async.AwaitTask
|> Async.RunSynchronously
|> Some
with e ->
display $"Req failed. Message: {e.Message}" |> ignore
None
match req with
| Some req when req.IsSuccessStatusCode && (isNull req.Content |> not) ->
let bytes =
req.Content.ReadAsByteArrayAsync()
|> Async.AwaitTask
|> Async.RunSynchronously
let format = Image.DetectFormat(bytes)
let guid = Guid.NewGuid()
let ext =
if isNull format || isNull format.Name then
String.Empty else "." + format.Name.ToLower()
let fileName = $"{guid}{ext}"
File.WriteAllBytes(Path.Combine(rawFolder, fileName), bytes)
Some (uri, guid, fileName)
| _ ->
display $"{uri}: could not be processed" |> ignore
None
let downloadedImages =
imgUrls
|> Array.ofList
|> Array.map downloadImage
I love writing code like this in interactive environments. It is impure, it doesn't try to gracefully recover from failed requests, it just forces its way through the list of URLs and downloads whatever works easily. Collecting data for neural networks - at least in my experience - is a process, that doesn't really care about single data points. You generally try to get a lot of data in acceptable quality. Because I usually have to process the images further at a later stage anyway it is more important to have code, that works reliably enough, is understandable for me or others and doesn't need too much maintenance. You might see why I like F# for this process. It offers me all the tools to write sound software but it also gives me enough freedom to get "pragmatic" whenever I need to.
A Word on Data
Far more important than the code to get the data is the data itself. Especially some sort of documentation how you got to it and how you processed it. You don't have to get extra fancy about it - at least in the beginning. You should get more strict if you ever build something, that has an actual impact on peoples lives, though. Might not be the hottest take of 2020 but if your work cannot be explained or reproduced (by others or by yourself) even a model working at a 99.99% accuracy is basically worthless. No pressure, though. For this app I tried to have some repeatability while keeping it really, really simple. All the image URLs and the search terms I used to get them go into one tab-separated-values (.tsv) file (tab separated because it is still a commonly used format and URLs don't contain tabs) while all the URLs of the files I actually managed to download - accompanied by a GUID and a file name - go into another. Those files contain enough information (at least in theory) to recreate the dataset I used further down the machine learning process. That's pretty important because I'd never be able to share the dataset without violating a million licenses 🙃
Other than general reproducibility the composition of the dataset is also pretty important. You thought the magic would lie in the the algorithms, didn't you? Well, they are pretty important but whatever you feed to the big-brain-very-smart-piece-of-software has a pretty high impact. How much examples do I have for each class? How similar are the backgrounds and general color schemes in each class? Do I have some systematic errors (e.g. all images are tilted by 15 degrees to the right) in one class which could lead the model to generalize something that has absolutely nothing to do with the dataset? Could it be, that my dataset has some inherent bias? I personally tried to build a balanced dataset (samples per class), have a varied depiction of different Krampus types (to generalize the special vibe of violence and catholic judgement), a good mix of Santa samples (to capture the general feel of jolliness) and a wide array of different people. I especially tried to have at least a fair amount of people with fur clothing (because Krampus is kind of furry), beards (as I said - furry) and people of color. I chose to be extra carful with the last set of images because many depictions of Krampus have a darker skin color than the majority of people living in the Alps. Forgetting about a potential source of misclassifications like that usually leads to a lot of embarrassing results in the long run.
That's a lot of thought about data, that has absolutely nothing to with neither programming nor math. Who would have guessed, that one of the most important aspects of building a Krampus detector is non-technical. I really want to hammer home the importance of having a set of people with diverse backgrounds and experiences on your team whenever you set out to "make a machine intelligent". I try to think a lot about this - even for a silly app like this one. I'm also 100% sure, that I missed a huge amount of possible biases in my dataset, because I'm just one guy with a limited amount of ways to see the world. Phew, what a serious topic. Now, back to the Krampus classifier.
Data Preparation
I imagine that most people (who would read such an article) already know this but machine learning algorithms are pretty picky about the data they consume. I plan to use a CNN based on the Inception v3 architecture. This means, that all images I want to use for training need to have fixed dimensions (299 by 299 pixels) and a label (Krampus, Santa or Other). The "easiest" way would be to just use a label which fits the search terms used to get to the images and resize them regardless of their current format or content. That's quick to automate but - unfortunately - pretty bad for the data quality. Just imagine all the mislabeled (bad search results) and badly distorted images. Going through all the images myself, labelling and cropping them to get the most out of my data is one of the most impactful tasks to increase the performance of my classifier. Unfortunately this is a lot of work. Cropping a couple hundred images using GIMP, writing down labels and documenting the bounding boxes used for the crop is a lot of tedious and error prone work. Now imagine scaling that process to two people, or three, or a dozen. That's not fun at all! Good, that it isn't particularly hard (compared to similar alternatives) to write an app to make this process far more efficient.
One of the coolest developments in the F# community is the SAFE Stack, an opinionated template using a set of libraries, that allows you to write full-stack web applications. Usually, this is the domain of startups and other enterprises, but researchers can make use of this as well. At Fable Conf 2018 Evelina Gabasova demoed an application used to preprocess news articles for further usage in fake news research. It was written using the SAFE stack, lived through multiple iterations and made users as well as researches pretty happy. Two years after that, the SAFE stack is even better suited for this sort of task. Libraries like Feliz greatly improve the developer experience while writing web UIs and projects like Fable.Remoting make it possible to get rid of almost all boilerplate code when creating client-sever applications. When I want to work on straight-forward web applications, I'm hard pressed to find something that makes me more productive than that.
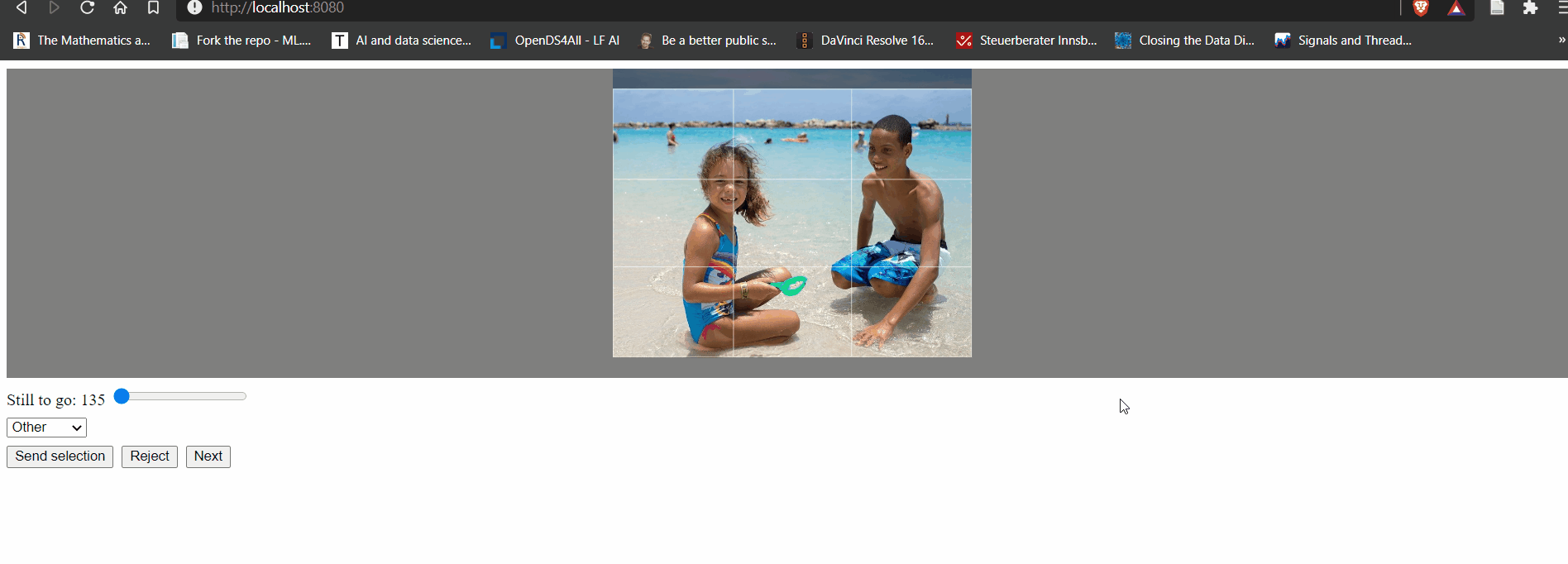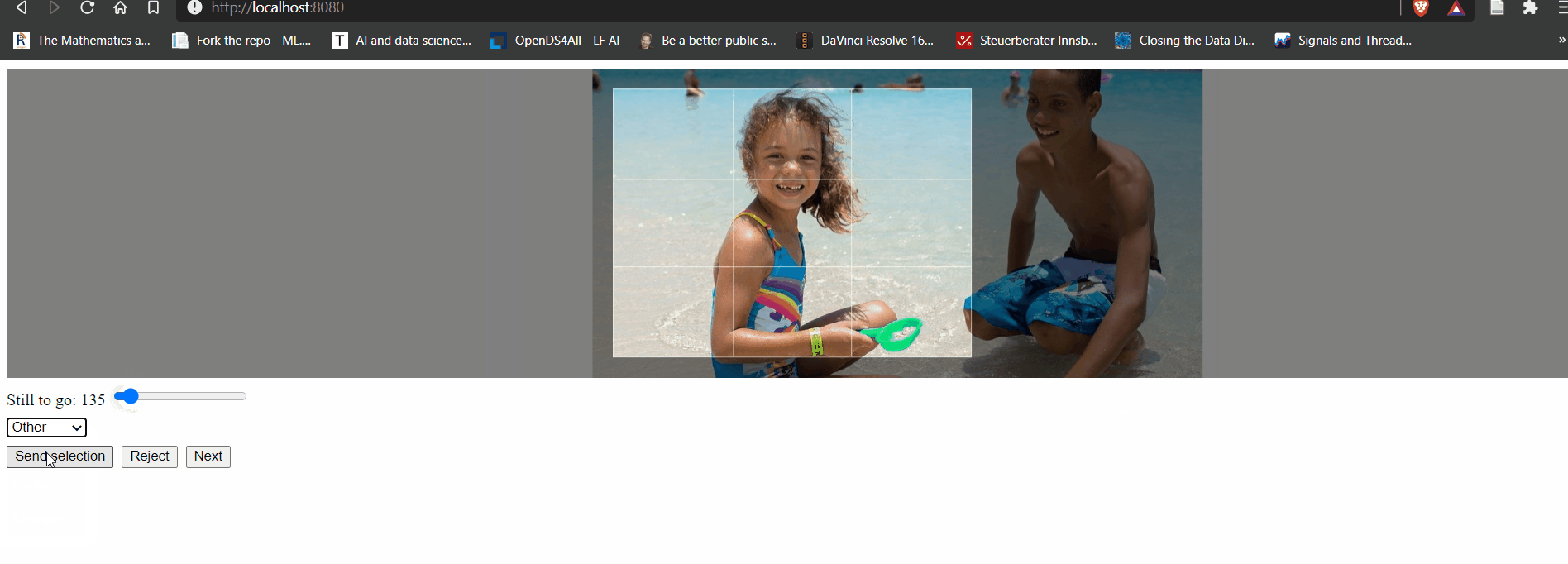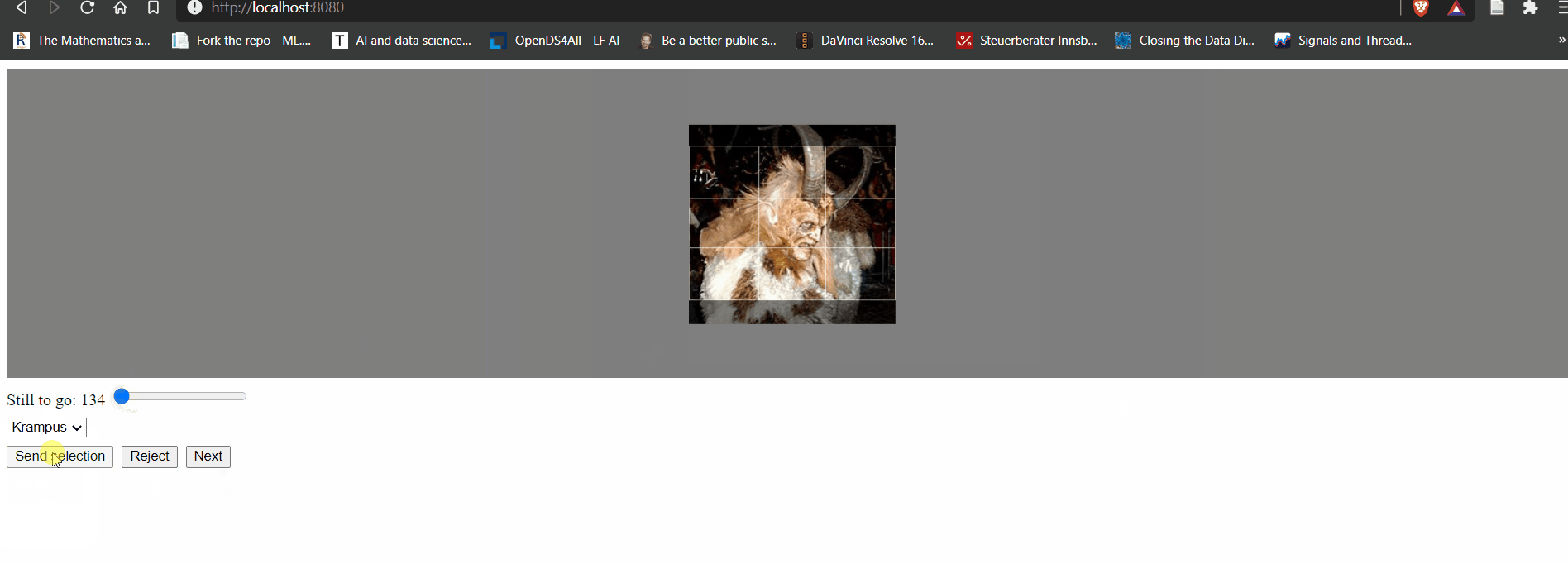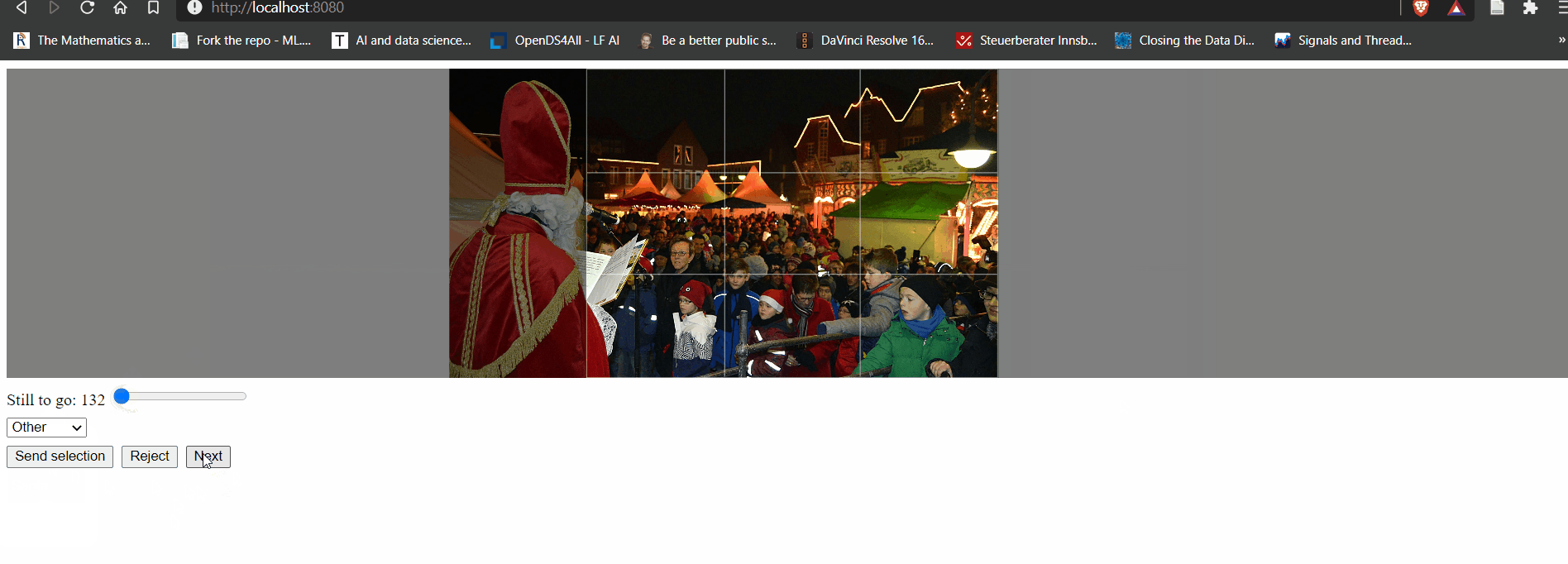
And as you can see it doesn't really take much to get where I wanted to go anyway. A simple UI, a couple of buttons and an element to create a bounding box for a crop. Batteries came basically included, only the cropping element was custom made and even that was achieved in almost no time by writing a Fable wrapper for the React Easy Crop component. The remote-procedure-call (RPC) API just included serving up random, unprocessed images, throwing away unfit images and receiving instructions to correctly apply crops (using ImageSharp - the best .NET cross-platform image processing library out there) and save the labels. If you want to look at my terrible code you'll find it in the the IsItKrampus.NET.DataSet.* projects in the accompanying repository.
Training the Model
Training the model is usually the step which interests people the most. It's also the place where I (and many practitioners if I'm not mistaken) spend the least amount of time. Not because I don't like it (I love it - even though I'm still basically at the very beginning of my journey) but because I usually use an existing set of tools rather than coming up with my own stuff. For this use-case I already know, that I want to use a CNN, I already know the architecture (Inception v3) and I already know I want to do it in .NET. ML.NET is an open source library developed by Microsoft which allows me to do exactly that.
ML.NET supports a couple of scenarios for image classification. You could take a custom model trained in Azure Cognitive Services and use ML.NET's Tensorflow API to consume it. You could use an ONNX (an open standard to represent machine learning models) model and use it to classify your images. Or, you could use transfer learning on top of an included pre-trained model. The last option allows you to train your model on your own machine while saving countless hours of training time (given that the pre-trained network and its pre-learned labels fits to your use case). Luis Quintanilla already wrote a long form article on image transfer learning using ML.NET for the F# Advent Calendar so I'll just focus on the tweaks I used to teach my computer how to alert me of Krampus.
One of the topics I haven't seen discussed yet in the ML.NET space is how to use data augmentation when using transfer learning. Data augmentation is a pretty nifty trick to increase the amount of data you have (by reusing samples you already prepared) and to help your network generalize better (by adding variation to your data like flipped or discolored images). For the lack of an existing transformer (and my lack of knowledge of how to write a good ML.NET transformer) I can't do this within the ML.NET pipeline. This isn't the biggest of problems as ML.NET allows me to take any IDataView and create a sequence out of it.
[<CLIMutable>]
type ImageDataAfterPreprocessing =
{ ImagePath: string
Image: byte[]
Label: string
LabelAsKey: UInt32 }
let preprocessedImagesTrainSet =
mlContext.Data.CreateEnumerable<ImageDataAfterPreprocessing>(trainSet,
reuseRowObject = false)
With this sequence of images, a couple of functions and ImageSharp, I can define a simple augmentation pipeline.
let turnRight (imgBytes: byte[]) =
use img = Image.Load(imgBytes)
let newImage = img.Clone(fun img -> img.Rotate(90f) |> ignore)
use ms = new MemoryStream()
newImage.SaveAsJpeg(ms)
ms.ToArray()
let turnLeft (imgBytes: byte[]) =
... omitted for brevity ...
let flipHorizontally (imgBytes: byte[]) =
... omitted for brevity ...
let grayScale (imgBytes: byte[]) =
... omitted for brevity ...
let randomlyAugment (augmentationBase: ImageDataAfterPreprocessing seq) (percentage: float) (augmentation: byte[] -> byte[]) =
let randomIndexesToAugment =
let n = Seq.length augmentationBase
Seq.init (int ((float n) * percentage)) (fun _ -> rnd.Next(0, n - 1))
let pick (idxs: int seq) (s: seq<'a>) =
let arr = Array.ofSeq s
seq { for idx in idxs -> arr.[idx] }
let augmentedImages =
augmentationBase
|> pick randomIndexesToAugment
|> Seq.map (fun img -> { img with Image = augmentation img.Image })
augmentedImages
let augmentedImages =
[ turnRight; turnLeft; flipHorizontally; grayScale ]
|> Seq.map (randomlyAugment preprocessedImagesTrainSet 0.1)
|> Seq.concat
As usual with the code I write in notebooks it has a lot of room for improvement (just imagine using this on ultra large sequences - yikes) but it gets the job done for now. What I do with those snippets of code is:
- Define a couple of augmentation functions which create manipulated copies of images
- Apply those augmentations to a randomly picked subset of all training images
- Collect all images in a final sequence
Getting back to an IDataView ready for training can be done using the same APIs used to create it in the first place.
let postAugmentationPipeline =
mlContext.Transforms.Conversion.MapValueToKey(inputColumnName = "Label",
outputColumnName = "LabelAsKey",
keyOrdinality = ValueToKeyMappingEstimator.KeyOrdinality.ByValue)
let augmentedTrain =
Seq.concat [ preprocessedImagesTrainSet; augmentedImages ]
|> fun dataset -> mlContext.Data.LoadFromEnumerable(dataset)
|> fun dv -> mlContext.Data.ShuffleRows(dv)
|> fun dv -> postAugmentationPipeline.Fit(dv).Transform(dv)
The only thing you have to really be aware of is the keyOrdinality parameter in the MapValueToKey transformer. If you look at the Modelling.ipynb notebook you will see a couple of operations which shuffle and partition the dataset. Mapping values to keys in ML.NET is usually done by value occurrence. That way you don't need need to have complete knowledge of all possible values beforehand. If you can't guarantee order, though, this can lead to a different set of key mappings. It happened to me because I wasn't aware of it and I lost quite some time on debugging why my network suddenly performed so poorly. After finding out where I made the mistake, finally, I could be happy about the sudden 40% increase of training data. Now, that you know, you hopefully never have to run into this error yourself.
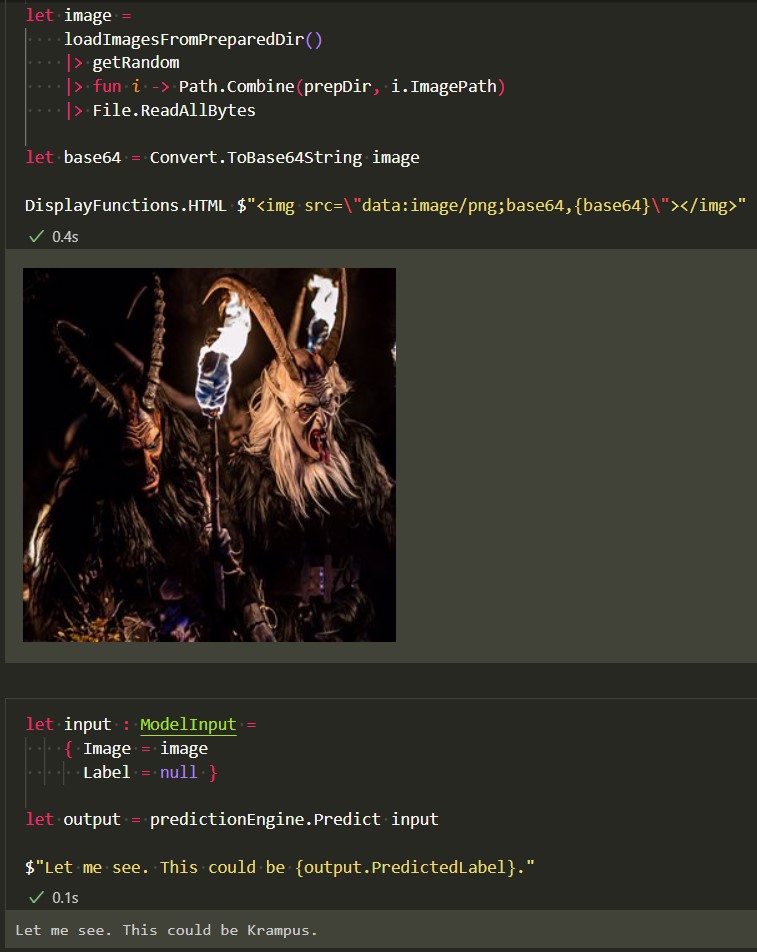
Now, that there is a trained model we can save it, load it, create a prediction engine and look at an example image. Oh no, it is Krampus! Quick, run!
Building an App
You can't finish an end-to-end demonstration without an end-product. For this project I thought about building a nice web application, that allows you to upload your own images or provide an image URI and classify them using some serverless component (because it is basically free to host and I'm short on cloud-money). Because I've never used it I went with the new Docker image based AWS Lambda functions and a Bolero (Blazor for F# people) frontend. The application isn't particularly exciting and should just demo how one might consume the model in the wild (to get away from Krampus).
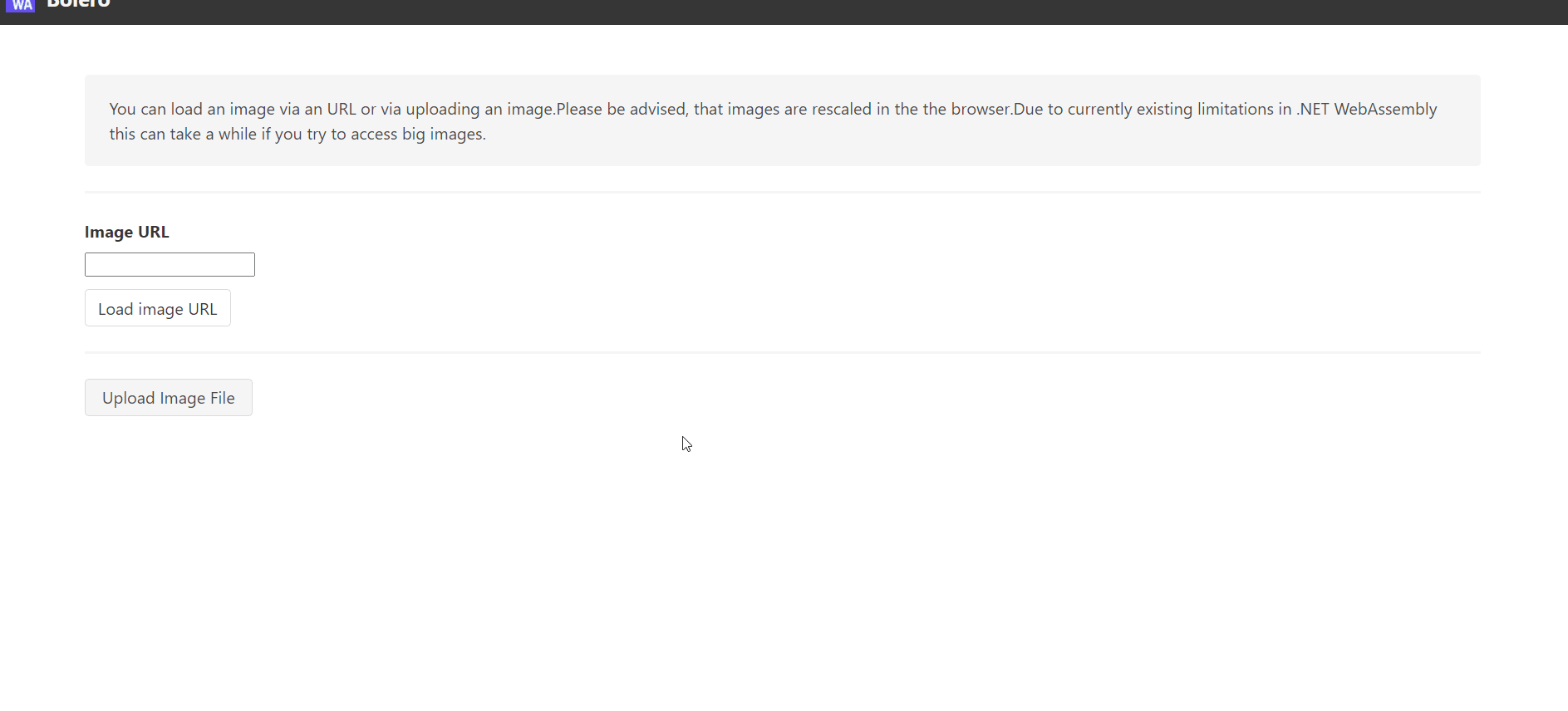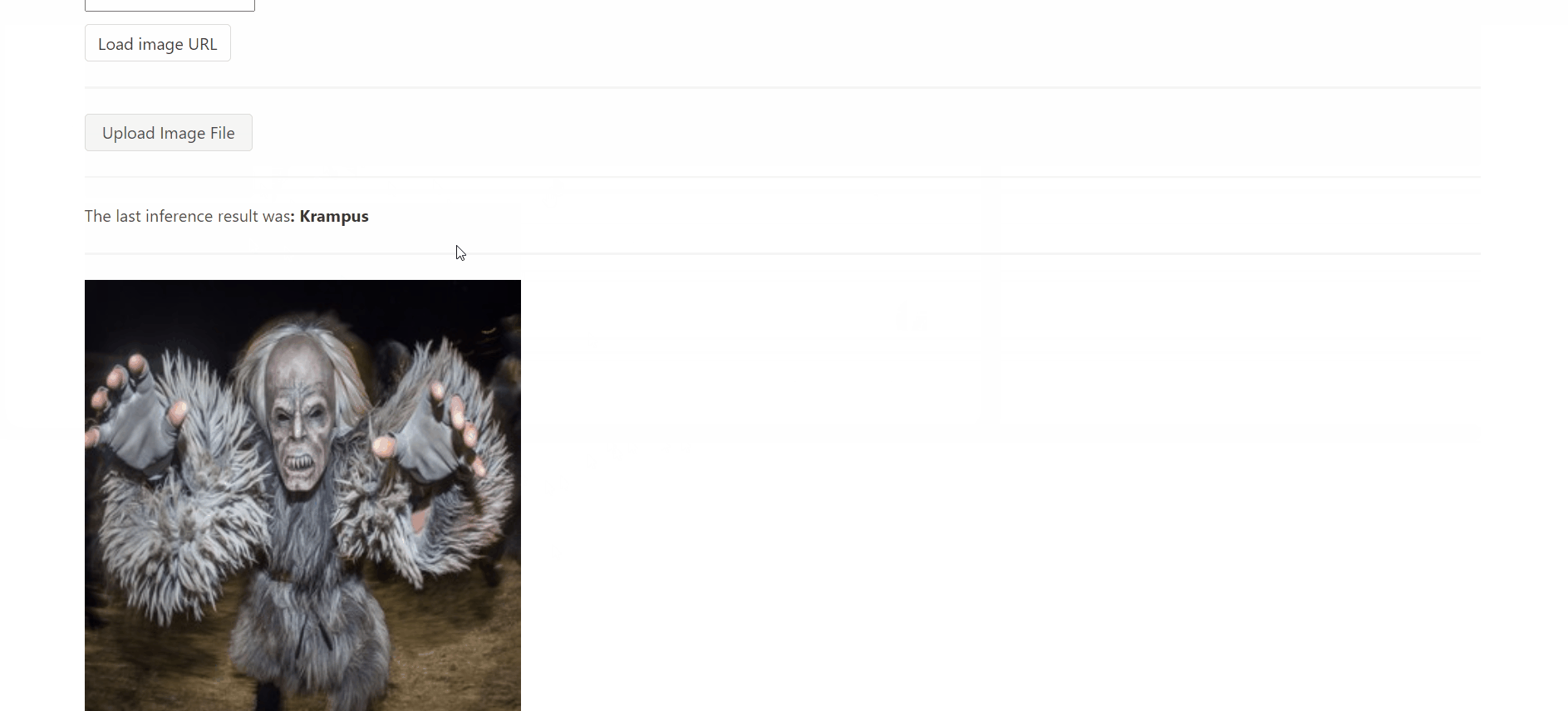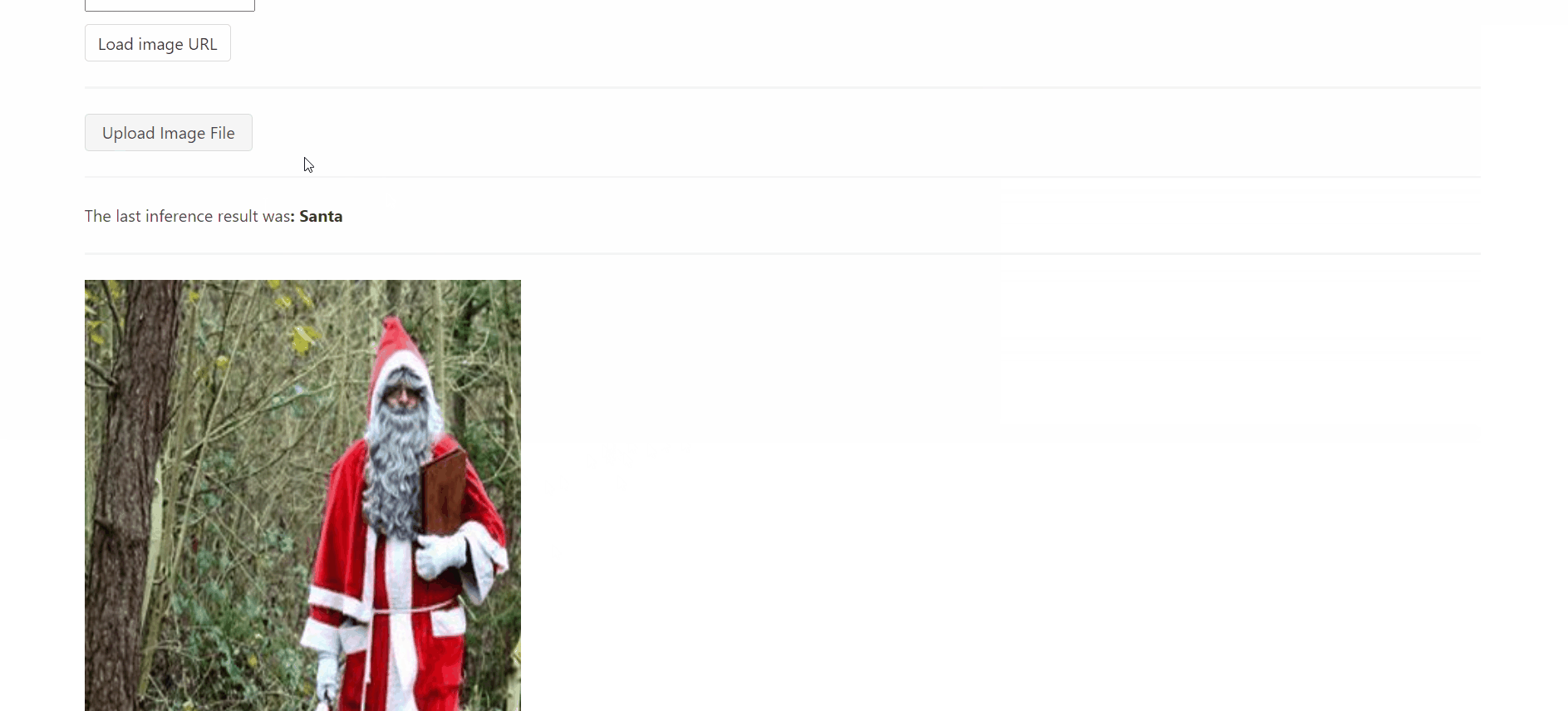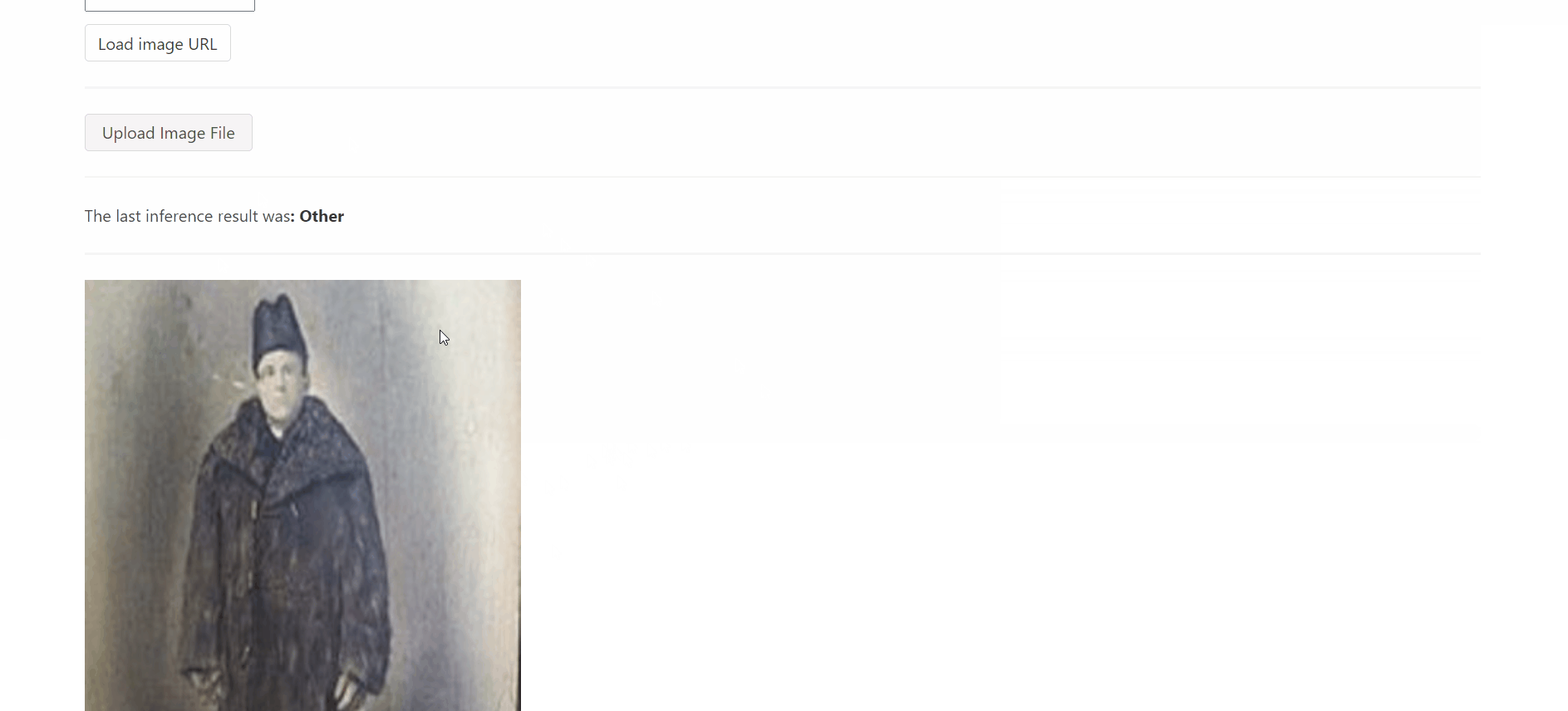
It works! At this point we can classify images from the safety of a nice web application. It's nothing special, really, but the interested reader might find some special bits in the source code. The IsItKrampus.NET.App.* folders in the accompanying repository contain all the bits necessary to work with this app and its backing Lambda function.
Where To Go From Here
When I set out to work on this project I wanted to do a bit more than I finally accomplished. Shocking, isn't it? Things I'd have on my list if I had more time to work right now would be:
Automation
FAKE is a F# build runner. It runs using F# script files which means, that you can pretty much every .NET library in your build and deploy scripts. No YAML, no special language - just good old honest F#. On this basis I could imagine incorporating ML.NET specific retraining and model deployment processes. FAKE plays well with every CI, that allows to execute dotnet tools (or arbitrary shell commands) so it is easy to integrate into virtually any CI/CD environment.
MLOps
ML Ops is the current specialized term to talk about continuous integration and continuous deployment but for machine learning related tasks. Alex Slotte has been writing MLOps.NET to tackle exactly this for ML.NET based models. It helps you to track experiments, log metrics, store versioned models and prepare deployments.
Deployment of the Inference App
I was a bold, bold boy to try out the more bleeding edge of technology for this use case. I learned a lot and there is a lot of fun stuff in this little experiment but I didn't manage to fully deploy the image based AWS Lambda function. As it was just some odd behavior with the API Gateway trigger (the thing that makes the function accessible via a plain old HTTP endpoint) I'd imagine, that it wouldn't take forever but that's hard to tell. I might - one day - write a follow up post on the progress.
Switching from Classification to Real Time Detection
Image classification is nice and relatively easy to handle with ML.NET. Unfortunately it isn't really build for real time video feeds and it doesn't really tell you how many "Krampus instances" are around you and where you would find them. Other network architectures like the famed YOLO are much better fits for this. Unfortunately ML.NET doesn't offer a way to do custom training for this network type. Maybe it will get added in the future, maybe it won't. In any case it might be possible to build something from scratch using DiffSharp or TensorFlow.NET. I could also just use Python...but that would be boring.